Random Forest
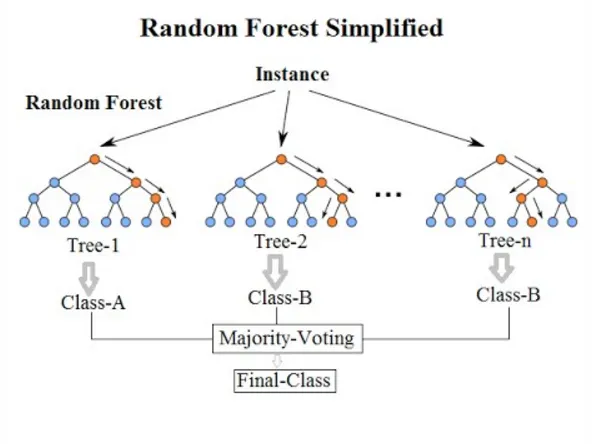
Random Forest is an ensemble learning algorithm that combines the predictions of multiple decision trees to make more accurate and robust predictions. The logic behind the algorithm is based on the concept of “wisdom of the crowd,” where the collective decisions of a group of individuals tend to be more accurate than the decisions of individual members.
Here’s how the Random Forest algorithm works:
1. Data Sampling: Random Forest builds multiple decision trees by randomly sampling the training data with replacement (bootstrap sampling). Each tree is trained on a different subset of the data, known as the bootstrap sample.
2. Feature Randomness: At each node of a decision tree, instead of considering all the features, Random Forest selects a random subset of features. This helps in reducing the correlation between individual trees and diversifying the forest.
3. Decision Tree Construction: Each decision tree is constructed using a recursive process called recursive partitioning. It splits the data at each node based on the selected features, by finding the best split that maximizes the information gain or Gini impurity.
4. Voting and Aggregation: Once the forest of decision trees is built, predictions are made by aggregating the predictions of individual trees. For classification problems, the class with the majority vote is selected as the final prediction. For regression problems, the average of the predicted values is taken.
Random Forest differs from a single decision tree in a few key ways:
1. Ensemble Approach: Random Forest combines multiple decision trees, whereas a single decision tree stands alone.
2. Randomness: Random Forest introduces randomness in both data sampling and feature selection, which helps in reducing overfitting and improving generalization.
3. Prediction Aggregation: Random Forest aggregates the predictions of individual trees to make the final prediction, whereas a single decision tree relies on the prediction of that tree alone.
Random Forest has various industrial applications, including Classification, Regression, Feature Importance, and Anomaly Detection.
1. Classification: It can be used for tasks such as spam detection, credit risk analysis, disease diagnosis, and sentiment analysis, where the goal is to classify instances into different classes.
2. Regression: Random Forest can be employed for predicting continuous numerical values, such as sales forecasting, price prediction, or demand estimation.
3. Feature Importance: Random Forest provides a measure of feature importance, which can be useful in feature selection and identifying the most relevant features for a given problem.
4. Anomaly Detection: By comparing the predictions of multiple trees, Random Forest can identify instances that deviate significantly from the norm, making it suitable for detecting anomalies in various domains, such as fraud detection or network intrusion detection.
Overall, Random Forest is known for its high accuracy, robustness against overfitting, and ability to handle high-dimensional data with a large number of features.
